
Python读取文件找到长度最大的单词
读取文件找到长度最大的单词
题目:程序根目录下的 word.txt 文件中保存有n个单词,每个单词一行。请使用Python编写一个一个程序,读取words.txt文件,统计长度最大的单词输出到控制台
输出结果如下:
1 | sophisticated:13 |
程序示例:
1 | w = [] # 存放文件中读出并经过处理的单词 |
解析(逐行):
第1行:
1 | w = [] # 存放文件中读出并经过处理的单词 |
定义一个列表,这里列表w用来存放从文件中读出并经过处理(去除单词两侧空格)的单词
第2行
1 | y = [] # 存放w中每个单词的长度 |
定义一个列表,这里列表y用来存放上面数组w中各个单词的长度
第3行
1 | with open('words.txt', 'r') as fp: # 以只读的方式打开word.txt |
使用 ’r’(只读模式)打开存在程序目录下的 ‘words.txt’ 文件,并给其指定变量==fp==
此处涉及一个with as语句和open()方法,下面是详细解释:
with as语句:
with as 语句的基本语法格式为:
1 | with 表达式 [as target]: |
此格式中,用 [] 括起来的部分可以使用,也可以省略。其中,target 参数用于指定一个变量,该语句会将 expression 指定的结果保存到该变量中。with as 语句中的代码块如果不想执行任何语句,可以直接使用 pass 语句代替。
通过使用with as 语句,==即便最终没有关闭文件,修改文件内容的操作也能成功==。
open()方法有两个参数:
open(‘参数1’,’参数2’)
参数1为要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
参数2为用于指定文件的打开模式。可选的==部分==打开模式如下表 所示。如果不写,则默认以只读(r)模式打开文件。
| 模式 | 含义 | 注意事项 |
|---|---|---|
| r | 只读模式打开文件,读文件内容的指针会放在文件的开头。 | 操作的文件必须存在。 |
| w | 以只写模式打开文件,若该文件存在,打开时会清空文件中原有的内容。 | 操作的文件必须存在。 |
| a | 以追加模式打开一个文件,对文件只有写入权限,如果文件已经存在,文件指针将放在文件的末尾(即新写入内容会位于已有内容之后);反之,则会创建新文件。 | / |
第4行
1 | for i in fp.readlines(): # 遍历文件每一行 |
循环遍历文件每一行
此处涉及一个readlines()方法,下面是详细解释:
readlines()方法
特点:一次性读取整个文件;自动将文件内容分析成一个行的列表
readlines()读取所有行,然后把它们作为一个字符串列表返回。
示例:
要读取的文档内容:
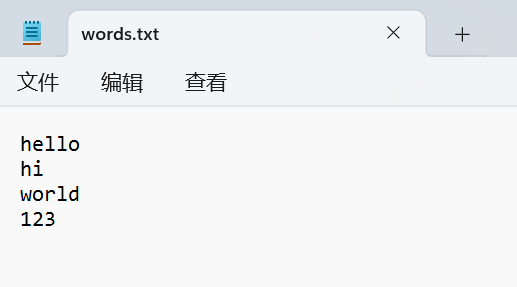
通过readlines()方法读取并输出:

==拓展:==
Python3中,读取文件还有另外两种方法:read()、readline()
read()方法:
特点:读取整个文件,将文件内容放到一个字符串变量中。
缺点:如果文件非常大,尤其是大于内存时,无法使用read()方法。
示例:
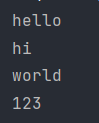
还是读取上面示例文档
通过read()方法读取并输出:
readline()方法:
特点:readline()方法每次读取一行;返回的是一个字符串对象,保持当前行的内存
缺点:一次只读一行,比readlines慢的多
示例:
还是读取上面示例文档
通过readline()方法读取并输出:

第5~7行
1 | if i.split(): # i不是空行 |
在循环遍历中,判断每一行是不是非空行,如果是非空行,把这行单词两边空格删除,并存入数组w
此处涉及三个方法:split(),strip(),append(),下面详细解释:
split()方法:
具体作用:拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
==此处仅用作判断是否非空行,如果是非空行,返回值1,继续运行if内部语句==
strip()方法:
具体作用:拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
==此处用来将第i行单词两边的空格删除==
append()方法:
方法append(obj),其中的参数obj为添加到列表末尾的对象
具体作用:用于在列表末尾添加一个元素
==此处用来将第i行单词添加到列表w的末尾==
第8~9行
1 | for i in w: # 遍历w |
循环遍历列表w,将列表w中各个单词的长度存入列表y
此处涉及两个方法:append(),len(),下面详细解释:
append()方法前面说过,此处不再赘述
len()方法:
作用:返回字符串、列表、字典、元组等长度
语法:len(str)
参数:str(要计算的字符串、列表、字典、元组等)
返回值:字符串、列表、字典、元组等元素的长度
==此处用来计算列表w中第i个单词的长度==
第10行
1 | m = max(y) # 找出长度最大值 |
找出列表y中长度最大值,并返回给变量m
此处涉及一个max()方法,下面详细解释:
max()方法:
主要作用:返回传入参数中的最大值
==此处用来找出列表y中各个单词长度的最大值==
第11~13行
1 | for j in w: # 遍历w |
循环遍历列表w,进行一个判断,找出列表w中单词长度为上面找出的最大值m的单词,输出这个单词和长度
此处涉及两个方法:len(),print(),下面详细解释:
len()方法上面已经说过,此处不再赘述
print()方法:
主要作用:打印输出字符串
==此处用来在控制台输出所找到的单词以及它的长度==
到此,该题大致完成
下面是部分Python基础语法:
for … in …
说明:也是循环结构的一种,经常用于遍历字符串、列表,元组,字典等
格式:
1 | for x in y: |
执行流程:x依次表示y中的一个元素,遍历完所有元素循环结束。
例1:遍历字符串
1 | s = 'I love you more than i can say' |
例2:遍历列表
1 | l = ['鹅鹅鹅', '曲项向天歌', '锄禾日当午', '春种一粒粟'] |
例3:遍历字典
1 | d = {'a':'apple', 'b':'banana', 'c':'car', 'd': 'desk'} |
致--小呆呆~




